CIO�r��APP�v�����]늴�W������Մ���c��I����Q��
����3��24�գ��]늴�Wܛ���WԺ�����ڸ�������CIO�r��APP�v����Ŀ�����}�顶���c��I����Q�ߡ������}���������w�Ĵ�����I����Q���еđ��ü���I���^��һЩ�����c�w��չ�_��
�����P�ڴ�����I�����еđ����҂�Ҫ�ش�����Ă����}����һ���@Щ���f����ʲô���}���ڶ����@Щ��������������������҂��ó���ʲô���������ģ��ڽY���еõ���ʲô��Ҫ���F������I����Q���еđ��ã�һ������Ҫ�кõĔ���֧�Σ���һ����t��Ҫ����Ĺ�����Փ�đ��á�ֻ�Д����c������Փ�Y���������ſ��ܕ��γ��µĹ���Q�ߵđ��ú�ģ�ͣ��@�nj����c��I����Q�ߵ����⡣
���������傀��������һ�ǻ��ں����Ļ��W�������®aƷ�_�l�Q�ߣ��ڶ��ǻ��ں������W�����ĸ����aƷ�����������ǻ�����I�罻�W�j�ĆT�������T�������y���о������������ò����ı��M���Ҹ��Мy���������ǻ������ھ��������������ھ�
����������ھ��uՓ�Ў�����I�ĮaƷ�OӋ�����õ��OӋ�aƷ�����y���®aƷ�OӋһ����ͨ�^�����ķ�ʽ�M�У��Ñ��I�ˮaƷ֮�����ºܶ��uՓ���@�N�uՓ���H�ϴ������Ñ��������҂��ܷ��@Щ�Ñ������D׃��aƷ�OӋ���ľS���Ñ����Ķ����M�aƷ�OӋ���҂��ܷ���Ŀ���ģ�������ھ��uՓ����֮�У��Ķ����F���ܼ��r�،��F�®aƷ�ĸ��M����ᘌ��֙C�aƷ���uՓ�����Ķ����_�l�^���У��֙C�®aƷ�_�l�^������������ھ��uՓ��ȡ�����Ķ������OӋ�����õظ��M�aƷ�OӋ��
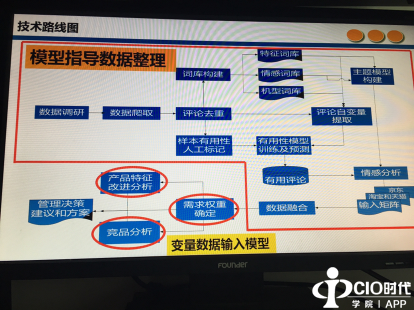
�����������ļ��g���D�У���������һ�������{�У��ľ��|���Ԍ�������������ȡ�҂���Ҫ�����֙C���������о����҂��xȡ��ʮ����Ҫ�������֙C�������ľ��|�ȾWվ���M�Д�������ȡ���@ȡ������֮���ڼ��g���D�п��Կ����M���˔������A̎�������а����uՓ��ȥ�أ���Ȼ߀��һ헺���Ҫ�Ĺ��������ӱ����������˹���ӛ���䌍���aƷ�OӋ�����ԣ���Щ�uՓ���aƷ�OӋ���]�ã��������M�����á�����ӱ��������Ԙ�ӛ֮���M��������ģ��Ӗ����ͬ�r�ڴ������uՓ�И�����һ����Ҫ��ȡ����������С��C�ͣ�����ڼ��g���У������������~�졢����~�졢�C���~�죬�ڴ˻��A�Ϙ����֙C�����}ģ�ͣ����}ģ����ָ����һ���~���������֙C�Ĵ��C�r�g�^�L�������M����еķ����������@헹������ٽY�Ϲ����еĿ���ģ���M�п͑��������������ģ�����ᵽ�͑��ĝM�����������������������@ϲ�����҂������Ñ�Ч��ֵ�Ĵ�С�M�����õ��Ñ���1���������汾�����ܡ����^���������ۺ�������2����������̎�������������Ļ����̖���l�ᡢ���C��3���@ϲ����늳ء��r���ָС�ϵ�y�������҂�Ҳ��������Ĺ��������ڻ��������������Ϸ��˜ʣ�Ŭ�����ͮaƷ�����ʺͷ���ʧ�`�ʣ����������������������ǿ��]���Ϸ��˜ʣ����������߷��˜ʡ�ͬ�ӌ����@ϲ�����������������������_�l�·��գ��������ݡ�
�����ڮaƷ�uՓ�д��ڲ�ͬ�aƷ�g�ĸ��N��ͬ���������ı��^���ڴ˻��A���҂����������һ������aƷ�ھ��u���aƷ���ھ��u�֞�aƷ���u�Ⱥ�֪���ȡ����u���֏Č������u�Ⱥ͌��ԙ��ɂ��Ƕ��M�п��]���͌��Ե����u�ȶ��ԣ�ǰ����^������ȡ���֙C��ÿ��������������늳ء���Ļ���ȴ�ȣ���ÿ�����Զ���һ���u�r�ľ��ֵ����һ�l�uՓ�Ќ�ij�����Ե�Ч��ֵ������Ӌ������Ե����u�ȣ����������Եę����M��Ӌ�㣬��ɵó���i�l�uՓ��ij���aƷ����j���u�r���Ķ��y������ͬ�aƷ���ھ��u���ڴ˰����У��҂�ᘌ��Ŀ��֙C�M�����о����քe�飺�A�顢IPhone�����ǡ��롣
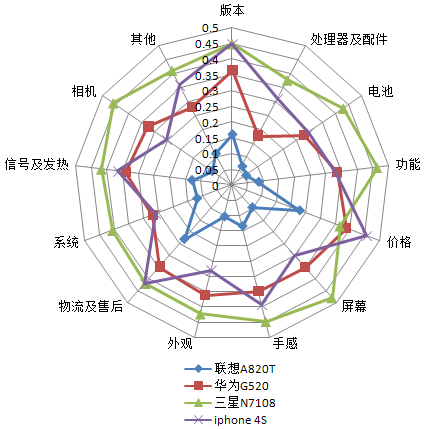
����������N7108�ĸ������Ե����u�Ⱦ�����������r����⣩�������u�ȸߣ�����A820T�ĸ������Ե����u�Ⱦ�����Ȍӣ������u����ͣ���iphone4S�Ĵ��Ե����u��������N7108���r����⣩���s�����A��G520�����C�����^����Ļ���⣩����ˣ��Č������u�Ȍ������������N7108���F�^�ã���������m�����{�c�r����A820T���w�϶���Ҫ������
�������Y�YԴ��������I�T���ĝ����о�һ��Ҳ�Ƕ���چ����M�У����@���҂�Ҳϣ��ͨ�^��I�Ȳ��罻�W�j�Ĕ������M�ІT�������Ĝy���о����҂��xȡ��ij��I�罻�W�j�ІT�����罻�������ڴ˻��A�Ϙ����ˌ��T���ĝ����֞��˅f�{������֪�R�����ɂ��S�ȡ��ڴ˻��A���Mһ������������ÿ��������ָ�˜y��������ͨ�^���ı������ķ����c�ھ������y����ÿ��ָ�˵�ֵ���Ķ��M�ІT������ָ���Ĝy���о���
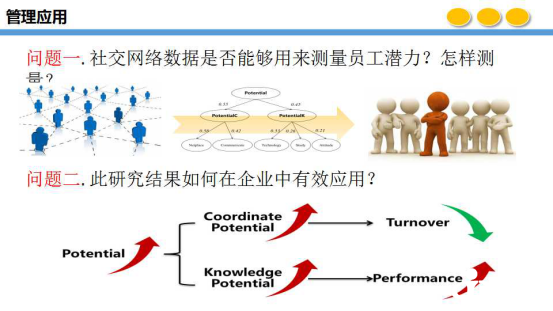
�����ܲ��������ı��M���������Ҹ��еĜy���أ����y��������Watson�����������PANAS�������y����е��Ҹ�ͨ�^�����ķ�ʽ�y��ij���˵��Ҹ��С����@�N�����ķ�ʽ�o�����F��Ҏģ�����؏͡��o�ɔ_�Ĝy����Ҳ�����f���ܶ����ڜyԇ�rδ��ӳ���挍�ĸ��顣��ˣ�Ҫ���F�o�ɔ_�´�Ҏģ�����؏͵Ĝy�����t��Ҫһ�����õؿ������ú������^�������Ԅӻ������y�����Ҹ����҂�����һ���y���Ҹ��е�ģ�ͣ���Ҫ�Ǐ�ijһƪ�����г��F������~�������l������ƪ��������ռ�ı�����������һ���ܴ�Ć��}�������ĵ�����~����Ҫ���������y���~��ܶ�ֻ�������ؓ�棬��ÿһ������~���]�е÷ֵı��^���@�ǹ����^���кܴ��һ���y�}��Ӣ�����й��_���~�죬���^�Ŭ�����҂��ҵ���Ren�~�졣
�������Կ������҂�ģ�͵ĽY���c���H��r�DZ��^���ϵģ��҂����vʷ�ѽ��l�����¼��ͬF��ģ�͵ĽY�������ǿ��Ԍ����ģ��@���҂����Ҹ������ò����ı����ĽY�����ش��¼��Č��ȡ�ͬ�ӣ��҂�Ҳ�����ܡ���ı��^����������ÿ��Ĕ����M�Ќ��Ⱥ�l�F��ÿ��Ķ��·�������^�ߵģ����ڶ��·��д������������Ҹ����_ʼ�½���ͬ�rʮһҲ����ˡ����ܵČ����У���һ�^�ͣ��ܶ��^�ߣ����ڹ������^ƣ�v���������^�ͣ����ڿ�����ĩ�ˣ�����֮�����_ʼ�������@���P���ش��¼��Č��ȡ�ÿ��߷�ͷ�Č����Լ�һ�ܵČ��ȡ�
������ˣ����@���о��У��҂�����������W�����^�Ҹ��Мy����PANAS�����������û��W�д����ǽY���������OӋ��һ���µ��Ҹ�������ģ�ͣ����F�ˌ�����Ҹ��еČ��r�ӑB�O�y��
����Ŀǰ������ӛ��Ҳ��ͨ�^���͡��罻�W�j�����İl�F����������ͨ�^��Ⱥ��QQȺ�����Ȱl�F����Щ���c�l���������Լ���֪�R�Д࣬�@�п�����һ��ֵ����ĕ��ɞ�һ�l������Ϣ���ڴ��^���п��ܞg�[�^һ�f�l���Űl�Fһ�lֵ���{�кͲ��L�γ����ă��ݣ��҂��Q֮�������������ȣ��҂�������һ�������������rֵģ�ͣ���������˾�������Ҫ�ԡ������Ժ͙�׃�ԡ��ژ��������������҂� ȡ�ˡ�����W��ӛ�ߣ��Լ�һЩ�����ҡ��Ŀ������M����ģ�͵ĸ��M���ڼ��g���D�п��Կ�����һ�����ǘ������rֵ����ģ�ͣ���һ�����ǏĔ������ҵ����������ڔ����ʂ��A�Σ���Ҫ���������������¼��M�����¼��|�l��ȡ���������w�R�e���r�g���_��ȡ���¼������ȡ�����������rֵģ���аl�F���@�Ă�Ҫ�،����rֵ���u�r�����õģ����@�Ă������M�г�ȡ���������¼���Ϣ���Ӗ�������yԇ�����Ķ��M�����rֵģ�͵�Ӌ�㣬�@��Ӌ���^����Ҳ�M����ģ�͵�Ӌ����{�����Խ�ͨ�¹ʞ�����ͨ�^�@���^�̿Ɍ�ijһ���c���н�ͨ���P������Ϣ������ȡ������������rֵ�M���u�֣����u���^���У����¼�������Խǰ�rֵԽ�ߡ�����ӛ�߶��ԣ��F��ֻ��Ҫ��һǧ�l������ԺY�x��������ľ������p�p�乤�������Ķ����õ��u�r�������п��ܴ��ڵ���������
�������ϱ����傀����İ������䌍������һ�����棬������ģ�͵đ����ǵڶ������棬��ģ�ͺ͔����Y�������������Д���Ҫ��Щ�����������f������Щ���}���Լ��@Щ����������Α��õ�����Q��֮�С�
- �˺�����I����֪�R�v��
- �����R��
- ���P����